
Loss Functions: Measuring AI’s Performance
In the ever-evolving world of artificial intelligence (AI), one term that often comes up is “loss function.” If you’re diving into AI and machine learning, understanding loss functions is crucial. These functions play a fundamental role in how AI systems learn and improve. So, let’s embark on this journey to uncover the mystery behind loss functions and how they measure AI’s performance.
What is a Loss Function?
At its core, a loss function is a method of evaluating how well an AI model’s predictions match the actual outcomes. Think of it as a report card for AI, where the lower the score, the better the AI’s performance. The loss function quantifies the difference between the predicted values and the actual values, providing a numerical value that represents this discrepancy. This numerical value is known as the “loss.”
The Role of Loss Functions in AI
Loss functions are pivotal in training AI models. During training, an AI model makes predictions, and the loss function calculates the error between these predictions and the actual data. This error is then used to adjust the model’s parameters through a process called optimization. By minimizing the loss, the model learns to make better predictions.
Types of Loss Functions
There are various types of loss functions, each suited for different types of tasks. Let’s explore some of the most commonly used ones:
Mean Squared Error (MSE)
Mean Squared Error is one of the simplest and most widely used loss functions for regression tasks. It measures the average of the squares of the errors, giving a higher penalty to larger errors. The formula for MSE is:
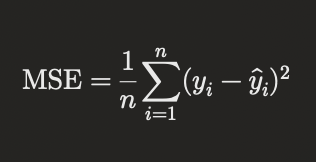
Where (y_i) is the actual value, (\hat{y}_i) is the predicted value, and (n) is the number of data points.
Cross-Entropy Loss
Cross-Entropy Loss is commonly used in classification tasks, particularly in binary and multi-class classification. It measures the difference between two probability distributions – the true distribution and the predicted distribution. The formula for binary cross-entropy is:
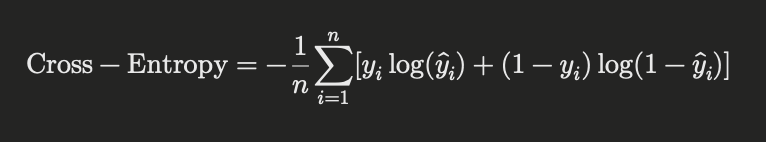
Hinge Loss
Hinge Loss is often used for training support vector machines (SVMs) and is suitable for binary classification tasks. It aims to ensure that the correct class scores are greater than the incorrect ones by a certain margin. The formula for Hinge Loss is:
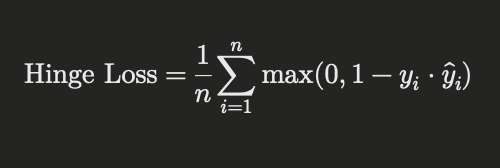
Why Different Loss Functions?
Different tasks and models require different loss functions to effectively measure and optimize performance. For example, regression tasks benefit from MSE because it penalizes larger errors more severely, making it ideal for continuous outputs. On the other hand, classification tasks often use Cross-Entropy Loss to handle probabilities and provide a more nuanced measure of performance.
Optimization and Gradient Descent
Once the loss is calculated, the next step is to minimize it. This is where optimization algorithms like gradient descent come into play. Gradient descent adjusts the model’s parameters to reduce the loss. It does this by computing the gradient of the loss function with respect to the parameters and updating the parameters in the opposite direction of the gradient.
The Importance of Loss Function Selection
Choosing the right loss function is crucial for the success of an AI model. An inappropriate loss function can lead to poor model performance, even if the underlying model is robust. Therefore, understanding the problem at hand and selecting the appropriate loss function is a critical step in building effective AI systems.
Common Challenges with Loss Functions
Despite their importance, working with loss functions comes with its own set of challenges. Let’s delve into some common issues that data scientists and AI practitioners face:
Overfitting and Underfitting
Overfitting occurs when a model learns the training data too well, capturing noise and anomalies that don’t generalize to new data. Underfitting, on the other hand, happens when a model is too simple to capture the underlying patterns in the data. Both overfitting and underfitting can affect the loss function, leading to misleading indications of performance.
Vanishing and Exploding Gradients
In deep learning, loss functions can be affected by vanishing or exploding gradients. This occurs when the gradients used in optimization become too small or too large, hindering the learning process. Techniques like normalization and advanced optimization algorithms help mitigate these issues.
Imbalanced Data
In classification tasks, imbalanced data can skew the loss function. If one class is significantly more frequent than others, the loss function might favor the majority class, leading to poor performance on minority classes. Strategies like class weighting and sampling techniques are used to address this challenge.
Advanced Loss Functions
As AI continues to evolve, so do the loss functions used to train models. Advanced loss functions are designed to handle more complex tasks and improve model performance. Here are a few examples:
Huber Loss
Huber Loss combines the best aspects of MSE and Mean Absolute Error (MAE). It is less sensitive to outliers than MSE and provides a more robust measure of performance. The formula for Huber Loss is:
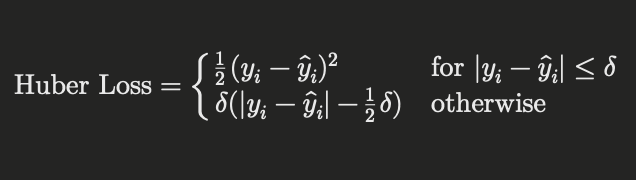
Where (\delta) is a threshold parameter.
Dice Loss
Dice Loss is commonly used in image segmentation tasks. It measures the overlap between the predicted segmentation and the ground truth, making it ideal for medical imaging and other applications where precise segmentation is critical. The formula for Dice Loss is:
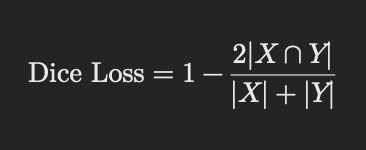
Where (X) is the predicted segmentation and (Y) is the ground truth.
Custom Loss Functions
In some cases, standard loss functions may not be sufficient to capture the nuances of a specific task. This is where custom loss functions come into play. By designing a custom loss function, you can tailor the learning process to better suit your specific requirements.
Creating a Custom Loss Function
Creating a custom loss function involves defining a mathematical formula that accurately measures the performance of your model. This often requires a deep understanding of the problem domain and the specific challenges involved. Custom loss functions are implemented by defining the function and its gradient with respect to the model parameters.
Use Cases for Custom Loss Functions
Custom loss functions are often used in specialized applications where standard loss functions fall short. For example, in financial forecasting, a custom loss function might be designed to minimize risk rather than just error. In reinforcement learning, custom loss functions can be used to optimize specific reward structures.
Evaluating Model Performance
While loss functions are essential for training AI models, they are not the only metric used to evaluate performance. Once a model is trained, it’s important to assess its performance using additional metrics to ensure it generalizes well to new data.
Accuracy
Accuracy is a simple and intuitive metric, especially for classification tasks. It measures the proportion of correct predictions out of the total number of predictions. However, accuracy can be misleading in cases of imbalanced data, where a high accuracy might not indicate good performance on minority classes.
Precision and Recall
Precision and recall are particularly useful for evaluating models on imbalanced data. Precision measures the proportion of true positive predictions out of all positive predictions, while recall measures the proportion of true positive predictions out of all actual positives. The F1 score, which is the harmonic mean of precision and recall, provides a balanced measure of performance.
AUC-ROC
The Area Under the Receiver Operating Characteristic Curve (AUC-ROC) is a powerful metric for binary classification tasks. It measures the model’s ability to distinguish between classes by plotting the true positive rate against the false positive rate. A higher AUC-ROC indicates better performance.
Practical Tips for Using Loss Functions
To effectively use loss functions in AI and machine learning projects, consider the following practical tips:
Understand Your Data
Before selecting a loss function, thoroughly understand your data and the problem you are trying to solve. This includes analyzing the data distribution, identifying potential outliers, and understanding the relationships between features and labels.
Experiment with Different Loss Functions
Don’t be afraid to experiment with different loss functions. Start with standard loss functions and evaluate their performance. If necessary, try advanced or custom loss functions to see if they offer better results.
Monitor Training Progress
During training, monitor the loss value and other performance metrics. This helps identify issues like overfitting, underfitting, or gradient problems early in the training process.
Use Regularization Techniques
Regularization techniques, such as L1 and L2 regularization, can help prevent overfitting by adding a penalty term to the loss function. This encourages the model to find simpler and more generalizable patterns.
Conclusion
Loss functions are the backbone of AI and machine learning, guiding the learning process and measuring performance. Understanding the different types of loss functions and their applications is essential for anyone working in this field. By carefully selecting and optimizing loss functions, we can build more accurate, efficient, and robust AI models.
Disclaimer
The information presented in this blog is for educational purposes only. The content is based on current knowledge and best practices in the field of AI and machine learning as of the date of publication. If you identify any inaccuracies or have suggestions for improvements, please report them so we can correct them promptly.